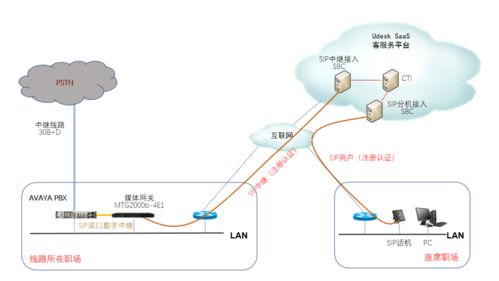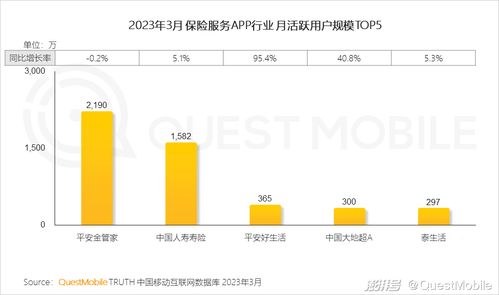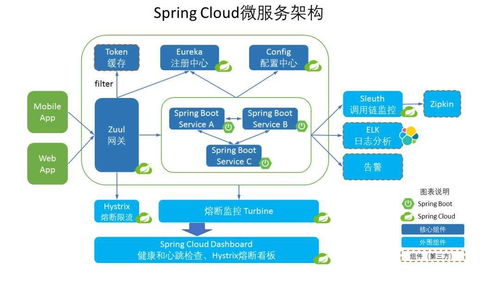
在數字化轉型的浪潮中,中小型互聯網公司面臨著業務快速迭代、數據量激增、系統復雜度提升等挑戰。為了應對這些挑戰,越來越多的企業開始探索微服務架構,尤其是在數據服務領域。微服務實踐不僅能提升系統的靈活性與可維護性,還能為數據驅動的業務決策提供堅實支撐。本文將探討中小型互聯網公司在微服務實踐中,如何優化數據服務的架構與實施策略。
一、微服務與數據服務的結合:為何重要?
微服務架構通過將單一應用拆分為多個獨立、松耦合的服務,實現了開發、部署和擴展的靈活性。對于數據服務而言,這種架構意味著可以將數據采集、處理、存儲和分析等功能模塊化,每個模塊專注于特定任務。例如,用戶行為數據采集、實時數據處理、離線數據倉庫等可以分別作為獨立服務運行。這種分離不僅提高了系統的可維護性,還使得團隊能夠針對不同服務進行技術選型,如使用Kafka處理實時流數據,用Hadoop進行批量分析,從而最大化效率和性能。
二、實踐中的關鍵步驟:從單體到微服務的過渡
對于中小型公司來說,直接全面轉向微服務可能帶來高昂的成本和風險。因此,漸進式遷移是更可行的策略。團隊可以識別出單體應用中的數據密集型模塊,如用戶畫像生成或日志分析,將其作為試點項目獨立為微服務。例如,一個電商平臺可能先從訂單數據處理服務開始,使用Docker容器化部署,并引入API網關來管理服務間通信。在過渡過程中,確保數據一致性和服務監控是關鍵——可以采用事件驅動架構(如使用RabbitMQ)來處理異步數據流,并利用Prometheus等工具監控服務健康度。
三、數據服務的微服務化:架構設計與挑戰
在微服務架構下,數據服務需要處理分布式數據管理、服務間通信和數據一致性等問題。中小型公司可以采用領域驅動設計(DDD)來劃分數據服務的邊界,確保每個微服務擁有自己的數據庫(如使用數據庫 per service 模式),避免共享數據庫帶來的耦合。例如,用戶服務管理用戶基本信息,而推薦服務則專注于用戶行為數據,兩者通過RESTful API或gRPC進行數據交換。這也帶來了挑戰:數據冗余可能增加存儲成本,跨服務查詢需要聚合層(如使用GraphQL)。實施數據版本控制和回滾機制,以及確保數據安全(如加密傳輸和訪問控制),都是實踐中必須考慮的環節。
四、工具與生態:支持微服務數據服務的實踐
中小型公司可以借助開源工具和云服務來降低微服務實踐的復雜度。例如,使用Kubernetes進行容器編排,實現服務的自動擴縮容;結合Apache Flink或Spark處理流數據和批處理任務;利用Elasticsearch提供快速數據檢索。在數據存儲方面,可以根據需求混合使用關系型數據庫(如PostgreSQL)和NoSQL數據庫(如MongoDB)。建立完善的CI/CD流水線,確保數據服務的快速迭代和部署。例如,通過Jenkins自動化測試和部署數據管道,減少人為錯誤。
五、案例分析:中小型公司的成功實踐
以一家在線教育平臺為例,該公司在微服務實踐中,將課程推薦數據服務獨立出來。原來,推薦邏輯與用戶管理系統緊密耦合,導致每次更新都需全系統重啟。通過微服務化,推薦服務使用Python Flask框架構建,獨立處理用戶學習行為數據,并通過Kafka接收實時事件。結果,推薦準確率提升了20%,且服務部署時間從小時級縮短到分鐘級。這個案例表明,即使資源有限,中小型公司也能通過聚焦核心數據服務,實現顯著的效率提升。
六、未來展望:微服務與數據智能的融合
隨著人工智能和機器學習的發展,微服務架構將進一步賦能數據服務。中小型公司可以探索將機器學習模型作為微服務部署,例如,使用TensorFlow Serving提供個性化預測服務。邊緣計算的興起也可能推動數據服務的分布式化,使得數據處理更接近用戶端。在實踐中,持續優化服務治理(如使用服務網格Istio)和培養團隊的全棧能力,將是保持競爭力的關鍵。
中小型互聯網公司在微服務實踐中,通過逐步遷移、合理設計架構和利用開源工具,可以高效地構建靈活、可靠的數據服務。這不僅提升了技術棧的現代化水平,還為業務增長奠定了數據基礎。在快速變化的市場中,這種實踐將成為企業數字化轉型的重要加速器。